
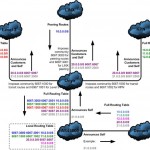
Имеем автономную систему (AS), несколько блоков адресов (PI), три внешних канала различной «толщины», с которыми происходит обмен по BGP.
Необходимо настроить балансировку нагрузки входящего и исходящего трафиков примерно равномерно между всеми каналами, учитывая «толщину трубы» каждого из каналов; необходимо так же настроить автоматическую переброску нагрузки при пропадании одного или нескольких каналов на оставшиеся, – и возврат в прежнее состояние при восстановлении пропадавших каналов.
В качестве роутера BGP используем сервер под управлением Linux с установленным пакетом Quagga.
Весь конфиг рассматривать не будем, – азы по конфигурированию BGP можно изучить в интернете. Затронем только важные по теме статьи вопросы.
Итак. Пишем номер нашей AS и id нашего роутера:
router bgp 12345 bgp router-id 1.1.1.1
Дальше переписываем сети, которые к нам непосредственно подключены, и которые мы жаждем анонсировать в мир:
network 1.1.1.0 mask 255.255.255.0 network 2.2.2.0 mask 255.255.255.0 network 3.3.3.0 mask 255.255.255.0 network 4.4.4.0 mask 255.255.254.0
Теперь описываем наших соседей, с которыми мы строим обмен по BGP:
neighbor 111.111.111.111 remote-as AS1 neighbor 111.111.111.111 description UPLINK_1 neighbor 111.111.111.111 update-source 111.111.111.112 neighbor 111.111.111.111 weight 3000 neighbor 111.111.111.111 route-map prepend_uplink1 out neighbor 111.111.111.111 prefix-list plup1in in
здесь:
- update-source 111.111.111.112 – бывает нужно. этим мы указываем, от какого IP соединяться с данным соседом. Если у вас есть свои блоки адресов, то роутер может пойти к соседям от IP из вашей сети, а BGP -обмен с соседом разумнее строить находясь в одной с ним сети (т.е. задействовать IP, выданный вам соседом);
- neighbor 111.111.111.111 weight 3000 – вес. Если вы получили от нескольких соседей маршруты на одинаковые направления, то в таблицу маршрутизации попадет тот маршрут, который пришел от соседа с наибольшим данным числом (весом);
- neighbor 111.111.111.111 route-map prepend_uplink1 out – назначаем свой route-map данному соседу. Это мы используем для балансировки входящего трафика;
- neighbor 111.111.111.111 prefix-list plup1in in – назначаем данному соседу свой prefix-list. Его мы используем для балансировки исходящего трафика.
Дальше расписываем еще двоих соседей по аналогии.
neighbor 222.222.222.222 remote-as AS2 neighbor 222.222.222.222 description UPLINK_2 neighbor 222.222.222.222 update-source 222.222.222.223 neighbor 222.222.222.222 weight 4000 neighbor 222.222.222.222 route-map prepend_uplink2 out neighbor 222.222.222.222 prefix-list plup2in in ! neighbor 333.333.333.333 remote-as AS3 neighbor 333.333.333.333 description UPLINK_3 neighbor 333.333.333.333 update-source 333.333.333.334 neighbor 333.333.333.333 weight 2000 neighbor 333.333.333.333 route-map prepend_uplink3 out neighbor 333.333.333.333 prefix-list plup3in in !
Теперь опишем наши префикс-листы для каждого соседа.
Для соседа номер «2» мы запрещаем прием маршрута по умолчанию (т.н. default) и разрешаем прием только маршрутов с маской сети меньшей или равной 19 (<= /19). Остальные маршруты мы от него принимать не будем.
ip prefix-list plup2in seq 5 deny 0.0.0.0/0 ip prefix-list plup2in seq 15 permit 0.0.0.0/0 le 19 ip prefix-list plup2in seq 25 deny any
Для соседа номер «1» мы запрещаем только прием маршрута по умолчанию:
ip prefix-list plup1in seq 5 deny 0.0.0.0/0 ip prefix-list plup1in seq 25 permit any
Для соседа номер «3» мы также просто запрещаем прием default’а:
ip prefix-list plup3in seq 5 deny 0.0.0.0/0 ip prefix-list plup3in seq 25 permit any
Т.е., с одного из аплинков (соседей) мы принимаем только сети, маска которых равная или меньше 19, а с двух других принимаем все маршруты. Маршрут по умолчанию не принимаем ни от кого – его мы впишем потом сами.
Теперь разберемся с route-map’ами. Для работы с рут-мапами нам понадобится написать еще парочку префикс-листов для каждого соседа. Эти префикс-листы нам пригодятся для регулирования входящего трафика. Суть такова: на каждого соседа мы должны описать, какие сети мы будем анонсировать с бОльшими препендами, а какие с меньшими. На одного соседа мы препендим одни сети, на другого – другие. И т.д. Таким образом получается, что с одного соседа к нам будет приходить трафик преимущественно идущий на одни наши сети, а с другого – на другие наши сети. Вот в следующих префикс-листах мы и описываем наши сети.
ip prefix-list plup1 permit 4.4.4.0/23 ip prefix-list plup1 deny any ip prefix-list plup1p permit 2.2.2.0/24 ip prefix-list plup1p permit 1.1.1.0/24 ip prefix-list plup1p permit 3.3.3.0/24 ip prefix-list plup1p deny any
Здесь мы создали два префикс-листа. В один попадает наша сеть 4.4.4.0/23, в другой – остальные наши сети. Точно так же расписываем префикс-листы для оставшихся соседей. Только сети при этом будут меняться.
ip prefix-list plup2 permit 2.2.2.0/24 ip prefix-list plup2 deny any ip prefix-list plup2p permit 4.4.4.0/23 ip prefix-list plup2p permit 1.1.1.0/24 ip prefix-list plup2p permit 3.3.3.0/24 ip prefix-list plup2p deny any ! ip prefix-list plup3 permit 1.1.1.0/24 ip prefix-list plup3 permit 3.3.3.0/24 ip prefix-list plup3 deny any ip prefix-list plup3p permit 4.4.4.0/23 ip prefix-list plup3p permit 2.2.2.0/24 ip prefix-list plup3p deny any
Настала очередь описать наши рут-мапы для каждого соседа. Смысл в том, чтобы для каждого аплинка создать рут-мап, где указать, какие сети анонсировать с препендом (и каким), а какие – анонсировать прямо.
route-map prepend_uplink1 permit 10 match ip address prefix-list plup1 ! route-map prepend_uplink1 permit 20 match ip address prefix-list plup1p set as-path prepend 12345 12345
С помощью данного рутмапа мы указали, что наши сети из префикс-листа plup1 (а это только сеть 4.4.4.0/23) через аплинк UPLINK_1 (111.111.111.111) будут анонсироваться без каких-либо изменений в длине маршрута. В то время как сети из префикс-листа plup1p (это три остальные наши сети) через того же аплинка мы будем анонсировать с препендом, и искусственно удлиним маршрут к этим сетям из мира через данный аплинк на два хопа (две AS). С другими аплинками суть точно та же, только маршрут мы там удлиняем на другие наши сети.
route-map prepend_uplink2 permit 10 match ip address prefix-list plup2 ! route-map prepend_uplink2 permit 20 match ip address prefix-list plup2p set as-path prepend 12345 12345 ! route-map prepend_uplink3 permit 10 match ip address prefix-list plup3 ! route-map prepend_uplink3 permit 20 match ip address prefix-list plup3p set as-path prepend 12345 12345 12345 12345 !
Теперь коснемся маршрута по умолчанию. Даже если вы получаете от аплинков full view, лучше иметь указывающий куда-то default.
Заходим в zebra через vtysh и указываем в качестве маршрута по умолчанию поочередно все наши три аплинка, только с разными дистанциями:
ip route 0.0.0.0/0 111.111.111.111 15 ip route 0.0.0.0/0 222.222.222.222 25 ip route 0.0.0.0/0 333.333.333.333 35
Т.е. мы указали в качестве default все три наших аплинка. В таблицу маршрутизации попадет тот маршрут, чья дистанция меньше остальных. Если какой-то маршрут отвалился, трафик пойдет по одному из оставшихся, чья дистанция теперь меньше – и т.д.
Что мы получили в итоге…
- UPLINK_1 (111.111.111.111). С него мы получаем все маршруты, кроме дефолта. Анонсируем в него 4-ю сеть (4.4.4.0) напрямую, остальные – с удлинением маршрута. Приоритет имеет 3000 (средний).
- UPLINK_2 (222.222.222.222). С него мы получаем только те маршруты, которые указывают на сети с маской меньшей либо равной 19. Анонсируем в него 2-ю сеть (2.2.2.0) напрямую, остальные с удлинением маршрута. Приоритет 4000 – наивысший.
- UPLINK_3 (333.333.333.333). С него мы получаем все маршруты, кроме маршрута по умолчанию. Анонсируем в него 1-ю и 3-ю сети напрямую, остальные – с удлинением маршрута. Приоритет 2000 – самый меньший.
Что получилось. Поскольку UPLINK_3 имеет самый маленький приоритет, то через него мы не ходим (хотя и получаем от него на всякий случай все маршруты). Так как с UPLINK_2 мы получаем только часть маршрутов (сети с маской <= 19), но приоритет у него самый высокий, — то как раз на эти сети с маской меньшей или равной 19 мы идем именно через этот аплинк. А вот на все остальные сети мы пойдем через UPLINK_1 – так как с него мы получаем все маршруты, и у него приоритет средний. Маршрут по умолчанию мы так же запустили через UPLINK_1.
Таким образом, часть трафика идет через UPLINK_1, часть – через UPLINK_2. Теперь если отвалится один из них – трафик пойдет через маршрут по умолчанию, т.е., через одного из них же (согласно указанной дистанции) – кто еще будет жив к тому времени. Если отпадут оба – в игру включится UPLINK_3, как последний оставшийся и имеющий самую длинную дистанцию. Если же отвалится UPLINK_3 – трафик будет ходить через одного из первых двух аплинков. Впрочем, через UPLINK_3 у нас исходящий трафик и так идет только в случае аварии – он у нас по сути как резерв.
С исходящим трафиком разобрались. Теперь что касается входящего.
Когда все везде включено и все каналы работают, трафик будет ходить так: на 4-ю сеть в основном будет приходить трафик с 1-го аплинка, на 2-ю – со второго, 1-ю и 3-ю – аплинка номер «3». Скорее всего, трафик на каждом аплинке будет будет проскакивать на каждую из ваших сетей, но преимущественно на каждом аплинке будет ходить трафик на те сети – которые в данный аплинк анонсируется без препендов. Трафик на остальные сети на данном аплинке будет составлять подавляющее меньшинство либо отсутствовать вообще (т.к. преимущественно будет ходить через другой аплинк, куда данные сети анонсировались без препендов).
В общем суть ясна. Теперь о главном. Какие сети, как и куда анонсировать, какие маршруты откуда получать – все это узнается преимущественно экспериментальным путем. В моем случае есть три внешних канала, больше 100 мбит каждый (но каждый разной «толщины»), одна автономная сеть, четыре блока адресов. Суммарный поток в среднем примерно 400 мбит.
По описанной выше технологии удалось равномерно распределить нагрузку как входящего, так и исходящего трафика между всеми внешними каналами. При этом обеспечивается полная жизнеспособность сети в случае если жив хотя бы один из внешних каналов. В случае восстановления «упавших» ранее внешних каналов, включение их в работу происходит автоматически, и вся система приходит в нормальное состояние, какое было до падения. Т.е. в случае аварий вмешательство человека в работу BGP и маршрутизации чаще всего не требуется, – при такой организации роутер прекрасно справляется сам.
Источник http://citforum.ru/nets/articles/bgp_load_balancing/
 RSS & RSS to Email
RSS & RSS to Email