
Для многих крупных высоконагруженных веб-проектов зачастую «узким»
местом в производительности становится скорость работы базы данных.
Можно добавлять память, тюнить те или иные параметры… Но в итоге чаще
всего всё упирается в диск.

Мы и сами на собственных проектах сталкивались с подобными «бутылочными
горлышками» (bottleneck), периодически наблюдая близкую к 100%
утилизацию диска в iostat.
О нашем опыте решения этого вопроса и хотим рассказать вам в этом посте…
Первое (и самое, казалось бы, очевидное) решение — надо использовать более быстрые диски.
Наиболее быстрые в настоящее время — наверное, SSD.
Работают SSD диски очень-очень быстро! Но…
- Требуется поддержка SSD в серверах (контроллер, драйверы).
- SSD — это дорого.
Даже выступавший на прошедшей недавно конференции «Highload++ 2011»
Домас Митузас (инженер по производительности баз данных в Facebook)
высказал примерно такую мысль: «Если бы мы могли везде использовать
SSD, нам бы вообще ничего не нужно было изобретать с точки зрения
производительности, вся наша работа не имела бы особого смысла«.
Другой подход — использовать не один, а несколько дисков. RAID, иначе говоря.
Мы уже писали о том, что собственные проекты размещаем в «облаке» Amazon. И удачно и успешно работаем с software RAID, собранными из EBS дисков Amazon.
Различных конфигураций RAID — очень много.
Наверняка, многие из вас уже видели и читали результаты тестов на EBS дисках в Amazon, опубликованные в MySQL Performance Blog.
Они достаточно любопытны и интересны, однако не очень устроили нас. В
основном, тем, что не корректно сравниваются очень разные результаты
(например, чтение с одного диска в один поток, RAID 0 — 8 потоков, RAID
10 — 4; и т.п.)
Поэтому мы решили провести собственное тестирование. Тем же инструментом — sysbench.
Мы решили работать с RAID 10. Именно он одновременно и быстрый, и
надежный. А, вот, различных его конфигураций — достаточно много.
Маленькое отступление. В процессе тестирования оценили еще одно очень важное преимущество «облака»: в
«облаке» очень удобно проводить самые разные тесты, собирая и разбирая
любые тестовые стенды! И при этом платить — только за время реального
использования!
Итак. Мы собрали 5 стендов.
1. single disk — 100 Gb
2. RAID 10 — 4 диска по 50 Gb
Добавили в админке Амазона 4 диска, подключили их, назначив соответствующие имена, а затем создали рейд вот так:# mdadm --create /dev/md0 --level=10 --raid-devices=4 /dev/xvd[g-j]
3. RAID 10 — RAID 0 из двух RAID 1 (каждый по 2 диска по 50 Gb)
Та же процедура, но итоговый рейд создается в три приема:# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/xvd[g-h]
# mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/xvd[i-j]
# mdadm --create /dev/md2 --level=0 --raid-devices=2 /dev/md[0-1]
4. RAID 10 — 8 дисков по 25 Gb
Аналогично пункту 2, но только подключаем 8 дисков, а не 4.# mdadm --create /dev/md0 --level=10 --raid-devices=8 /dev/xvd[g-n]
5. RAID 10 — RAID 0 из четырех RAID 1 (каждый по 2 диска по 25 Gb)# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/xvd[g-h]
# mdadm --create /dev/md1 --level=1 --raid-devices=2 /dev/xvd[i-j]
# mdadm --create /dev/md2 --level=1 --raid-devices=2 /dev/xvd[k-l]
# mdadm --create /dev/md3 --level=1 --raid-devices=2 /dev/xvd[m-n]
# mdadm --create /dev/md4 --level=0 --raid-devices=4 /dev/md[0-3]
На всех тестовых стендах использовалась файловая система ext4. Параметры монтирования: noatime,nodiratime,data=writeback,barrier=0
Для тестов использовался sysbench — на файле 256 Мб; режимы — random
read, random write, random read/write; разным количеством потоков — от 1
до 16.
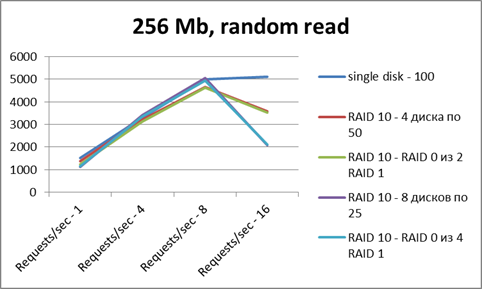

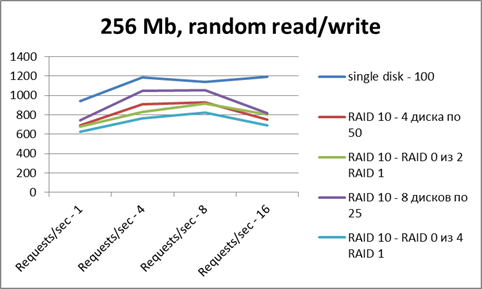
Ось X — число потоков
Ось Y — число операций в секунду.
По чтению — все сопоставимо по результатам. Рейд не дает особого преимущества.
Но картинка эта — весьма искаженная, так как на результаты очень сильно
повлиял файловый кэш (тестовый файл помещается в RAM целиком).
По записи рейды несколько проигрывают (сказываются некоторые накладные расходы).
* * *
Любой вопрос, начинающийся со слов «Что лучше…» не имеет смысла сам по себе.
Какая CMS лучше?
Какую выбрать базу данных?
Что лучше выбрать в качестве RAID’а?
При любом выборе всегда важны поставленные и решаемые задачи!
Мы выбираем дисковую систему для базы. Формат хранения данных у нас — InnoDB.
Это значит, что, в основном, мы работаем с большими файлами (несколько Гб) ibdata.
Типичный профиль нагрузки — random read/write (чтений больше).
И вот уже исходя из более понятной реальной задачи, делаем новую серию тестов — на файле размером 16 Гб.



- Чтение — один диск сразу упирается в потолок. Увеличение количества потоков не дает прироста производительности.
- Рейды из 4 дисков на нескольких потоках дают прирост производительности в 3-4 раза. Рейды из 8 дисков — в 6-7 раз.
- На запись — примерно та же картина, что и с одним диском.
* * *
Резюмируем.
Типичная работы базы MySQL — random read/write, чтений больше, чем записи. Самые производительные для такой задачи — RAID 10 с большим количеством дисков.
Минус такого решения — в удвоенной стоимости дисков (что при текущей их стоимости не является критичным).
Главный плюс — у нас есть простое решение (software RAID можно собрать как на физическом сервере, так и в «облаке») для масштабирования производительности дисковой системы.
 RSS & RSS to Email
RSS & RSS to Email